Начало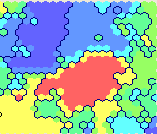
Тема исследования связей в социальных сетях становится все более актуальной по разным причинам: попытка ответить на вопрос о степени связности участников сетей; скорости и путях распространения информации; об эффективности целевой рекламы, в конце концов. Да и сам процесс исследования и поиска неявных связей затягивает! Для своих исследований в этом направлении я выбрал самый «кипящий» кусок рунета, а именно – русский сегмент Живого Журнала. Туманно сформулированный вопрос звучал примерно таким образом: можно ли выделить блоггерские «группировки» исходя из структуры связей между пользователями сервиса ЖЖ, т.е. располагая лишь информацией о «френдах». Выдвинув в качестве рабочей гипотезы идею о том, что подобную информацию можно извлечь из анализа аудиторий популярных журналов я столкнулся с задачей получения достоверных данных об этих аудиториях. Базовые средства сервиса livejournal не дают возможность получить полный список читателей блога мультитысячника. Поэтому, первым шагом, пришлось собрать структуру связей русского ЖЖ на домашнем компьютере. Забегая вперед скажу: социальный граф русского ЖЖ в моем исследовании имеет 2,08 млн. вершин и 58,05 млн. дуг. Интересно? Тогда под катом довольно много букв, цифр и картинок. Для своих исследований в этом направлении я выбрал самый «кипящий» кусок рунета, а именно – русский сегмент Живого Журнала. Туманно сформулированный вопрос звучал примерно таким образом: можно ли выделить блоггерские «группировки» исходя из структуры связей между пользователями сервиса ЖЖ, т.е. располагая лишь информацией о «френдах». Выдвинув в качестве рабочей гипотезы идею о том, что подобную информацию можно извлечь из анализа аудиторий популярных журналов я столкнулся с задачей получения достоверных данных об этих аудиториях. Базовые средства сервиса livejournal не дают возможность получить полный список читателей блога мультитысячника. Поэтому, первым шагом, пришлось собрать структуру связей русского ЖЖ на домашнем компьютере. Забегая вперед скажу: социальный граф русского ЖЖ в моем исследовании имеет 2,08 млн. вершин и 58,05 млн. дуг. Интересно? Тогда под катом довольно много букв, цифр и картинок. Выдвинув в качестве рабочей гипотезы идею о том, что подобную информацию можно извлечь из анализа аудиторий популярных журналов я столкнулся с задачей получения достоверных данных об этих аудиториях. Базовые средства сервиса livejournal не дают возможность получить полный список читателей блога мультитысячника. Поэтому, первым шагом, пришлось собрать структуру связей русского ЖЖ на домашнем компьютере. Забегая вперед скажу: социальный граф русского ЖЖ в моем исследовании имеет 2,08 млн. вершин и 58,05 млн. дуг. Интересно? Тогда под катом довольно много букв, цифр и картинок. Забегая вперед скажу: социальный граф русского ЖЖ в моем исследовании имеет 2,08 млн. вершин и 58,05 млн. дуг. Интересно? Тогда под катом довольно много букв, цифр и картинок. Сбор информации
По оценкам сервиса Яндекс.Блоги русский сегмент Живого Журнала насчитывает чуть более 2 млн. блогов. Взяв этот список за основу я проделал некоторую автоматизированную работу по заполнению базы данных «дружеских» отношений между блогами, позволяющую ответить как минимум на один вопрос: кто читает конкретный блог.Немного цифр
Были собраны связи 2,08 млн. пользователей. Т.е. граф с 2,08 млн. вершинами получил еще 58,05 млн. дуг(направленных отношений дружбы между пользователями) на 13.03.2011. Причем, только половина – 1,08 млн. пользователей читает кого-то еще (имеет исходящую дугу) и 1,26 млн. имеют читателей. В качестве иллюстрации можно привести некоторую статистику по количеству френдов (читателей): В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги. В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги. В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги.
В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги. В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги. В базу не вошли связи, которые были направлены за пределы «русского сегмента» (это где-то чуть более 6 млн. дуг к 0,9 млн. вершин) которые не исследовались дополнительно и отнесены к «иностранным» хотя и там попадают живые русские блоги. Оценка погрешности
Для оценки полноты собранного графа сравним «официальное» количество читателей из топа livejournal.com с количеством для тех же блоггеров, но полученным суммированием входящих дуг на графе. Для большей точности были взяты два фрагмента ТОП-50: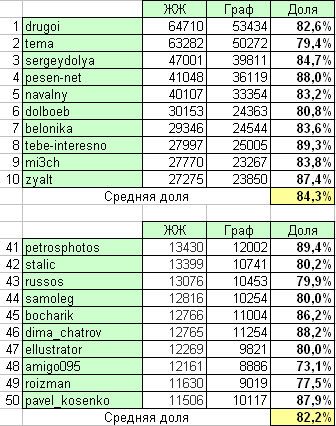 Как видим из таблицы, сформированный граф читателей соответствует реальному чуть больше чем на 80%. Погрешность может быть обусловлена изначальной изоляцией «русского сегмента» (т.е. исключением зарубежных френдов) и неполнотой самого списка русских журналов. В будущем возможно некоторое незначительно уточнение структуры локального графа. Анализ пересечения аудиторий ТОП-10 Сам анализ простой и плоский – берем списки читателей каждого блога из ТОП-10 и ищем их пересечение, занося результаты в табличку. Точнее в две таблички – в абсолютную, с количественными значениями и относительную – с указанием процента перекрытия аудиторий.
Как видим из таблицы, сформированный граф читателей соответствует реальному чуть больше чем на 80%. Погрешность может быть обусловлена изначальной изоляцией «русского сегмента» (т.е. исключением зарубежных френдов) и неполнотой самого списка русских журналов. В будущем возможно некоторое незначительно уточнение структуры локального графа. Анализ пересечения аудиторий ТОП-10 Сам анализ простой и плоский – берем списки читателей каждого блога из ТОП-10 и ищем их пересечение, занося результаты в табличку. Точнее в две таблички – в абсолютную, с количественными значениями и относительную – с указанием процента перекрытия аудиторий. 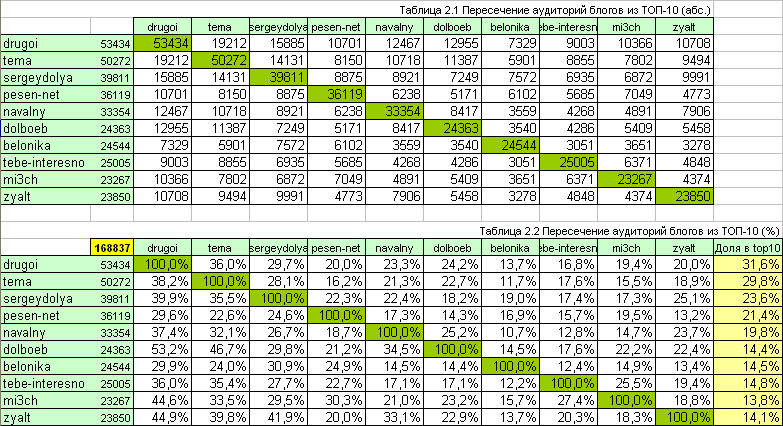 Во-первых, из второй таблицы видно, что общая аудитория журналов из ТОП-10 (т.е. людей, подписанных хотя бы на один топовый блог): 168837 человек (при этом помним про погрешность). Во-вторых, можно сказать, что треть (34,5%) аудитории Антона Носика (dolboeb) читает так же и Навального (navalny), а вот из читатей Ники Белоцерковской (belonika) того же Навального читает лишь 14,5%. Зато 30,9% ее читателей так же с нетерпением ждут новых отчетов Сергея Доли (sergeydolya) и аж четверть (24,9%) – историй из жизни Славы Сэ (pesen_net). И, кстати, почти половина (46,7%) читателей того же Антона Носика следит за перемещениями по тундре Артемия Лебедева (tema), а 20% аудитории лидера топа Рустема Адагамова (drugoi) любит получать горячие фотоотчеты нашей политической движухи от первоисточника – Ильи Варламова (zyalt). В-третьих, можно построить и взаимопересечения аудиторий более высоких порядков. Например, анализ пересечений аудиторий трех блоггеров представляет собой куб. Так срез подобного куба по Алексею Навальному даст следующую картинку:
Во-первых, из второй таблицы видно, что общая аудитория журналов из ТОП-10 (т.е. людей, подписанных хотя бы на один топовый блог): 168837 человек (при этом помним про погрешность). Во-вторых, можно сказать, что треть (34,5%) аудитории Антона Носика (dolboeb) читает так же и Навального (navalny), а вот из читатей Ники Белоцерковской (belonika) того же Навального читает лишь 14,5%. Зато 30,9% ее читателей так же с нетерпением ждут новых отчетов Сергея Доли (sergeydolya) и аж четверть (24,9%) – историй из жизни Славы Сэ (pesen_net). И, кстати, почти половина (46,7%) читателей того же Антона Носика следит за перемещениями по тундре Артемия Лебедева (tema), а 20% аудитории лидера топа Рустема Адагамова (drugoi) любит получать горячие фотоотчеты нашей политической движухи от первоисточника – Ильи Варламова (zyalt). В-третьих, можно построить и взаимопересечения аудиторий более высоких порядков. Например, анализ пересечений аудиторий трех блоггеров представляет собой куб. Так срез подобного куба по Алексею Навальному даст следующую картинку:  Матрица получается симметричной относительно главной диагонали. Цифры означают долю от общей аудитории двух журналов (пересечении строки и столбца), которые еще и читают Алексея Навального (navalny). Из таблицы можно видеть, что только треть (34,4%) общей аудитории блогов tema и drugoi читают еще и navalny, а вот от аудитории zyalt и dolboeb его читают почти две трети – 64,2%. Минимальный интерес к борьбе с коррупцией в режиме онлайн проявляют аудитории belonika-sergeydolya (26,6%) и belonika-pesen_net (25,5%). Ну и, в-четвертых, если вы занимаетесь размещением рекламных постов в блогах тысячников и не имеете подобных раскладов по ТОП-50 – увольте маркетолога :)
Матрица получается симметричной относительно главной диагонали. Цифры означают долю от общей аудитории двух журналов (пересечении строки и столбца), которые еще и читают Алексея Навального (navalny). Из таблицы можно видеть, что только треть (34,4%) общей аудитории блогов tema и drugoi читают еще и navalny, а вот от аудитории zyalt и dolboeb его читают почти две трети – 64,2%. Минимальный интерес к борьбе с коррупцией в режиме онлайн проявляют аудитории belonika-sergeydolya (26,6%) и belonika-pesen_net (25,5%). Ну и, в-четвертых, если вы занимаетесь размещением рекламных постов в блогах тысячников и не имеете подобных раскладов по ТОП-50 – увольте маркетолога :) Как объять необъятное?
С одной стороны, численных данных достаточно для проведения различных прикладных исследований. С другой стороны, для некоторых исследователей просто необходимо оценить визуально рабочее поле. Давайте попробуем покрутить данные перед глазами. Как? Тут нам пригодятся методы наглядного представления многомерных данных с понижением размерности: попробуем «втиснуть» наш 10-ти мерный набор данных (блоггеров, читающих журналы из ТОП-10) в двумерную картинку на плоскости. При этом, в идеале, было бы неплохо получить некоторую группировку читателей по читаемым блогам. Не очень запутано? Первый вариант группировки – провести кластеризацию алгоритмами g-means (кластеризация с автоматическим определением количества кластеров) или k-means (кластеризация по заданному количеству кластеров). В принципе, мысль здравая, но этот подход не решает проблемы отображения полученных результатов и имеет свои недостатки с учетом структуры наших данных. Поэтому я попытался воспользоваться своим любимым инструментом кластеризации – самоорганизующимися картами Кохнена в реализации аналитической системы Deductor (версия Academic) от компании BaseGroup Labs. Детали алгоритма можно почитать в соответствующих публикациях, скажу лишь, что в данной задаче важна его способность проецировать многомерный рельеф данных на плоскость отображения. То, что получается в результате и то, как именно интерпретировать его – сильно зависит от параметров обработки и пониманием природы обрабатываемых данных. Поэтому, дальнейший анализ – это частный случай, не претендующий на абсолютную истину. Итак, после скармливания выборки нейронной сети, которая и является картой Кохонена, получаем вот такую картинку. Количество кластеров (разноцветных зон в правом нижнем окне) чуть подрегулировано вручную – поставил 7 штук (нумерация 0..6) — для лучшей визуальной разбивки результата.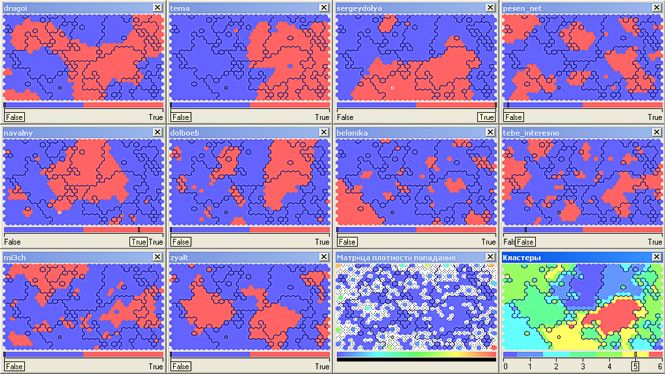 Чуть помедитировав на красивую и непонятную картинку можно перейти к некоторому поверхностному анализу. Так, аполитичный кластер (номер 2, почти 19 тыс. участников) поклонников Ники Белоцерковской (belonika), в основном имеет пересечения с читателями журналов drugoi, sergeydolya, pesen_net, mi3ch (выделенный кластер имеет заливку сеточкой):
Чуть помедитировав на красивую и непонятную картинку можно перейти к некоторому поверхностному анализу. Так, аполитичный кластер (номер 2, почти 19 тыс. участников) поклонников Ники Белоцерковской (belonika), в основном имеет пересечения с читателями журналов drugoi, sergeydolya, pesen_net, mi3ch (выделенный кластер имеет заливку сеточкой): 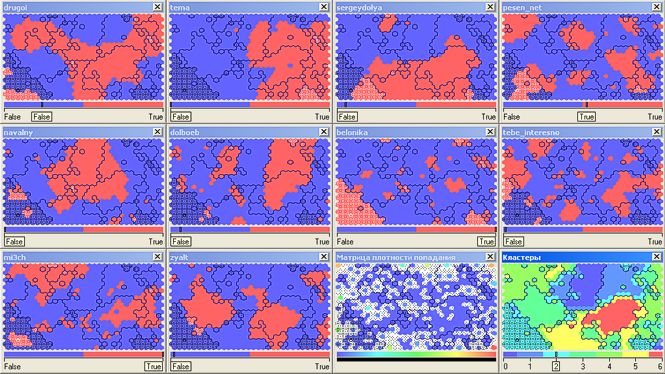 Творческая интеллигенция, читающая Славу Сэ (pesen_net), Дмитрия Чернышева (mi3ch), любующаяся на красивые картинки из журналов drugoi и tebe_interesno а так же обсуждающая дизайнерские находки Артемия Лебедева (tema) сгруппированы в кластер номер 4 (54,5 тыс.):
Творческая интеллигенция, читающая Славу Сэ (pesen_net), Дмитрия Чернышева (mi3ch), любующаяся на красивые картинки из журналов drugoi и tebe_interesno а так же обсуждающая дизайнерские находки Артемия Лебедева (tema) сгруппированы в кластер номер 4 (54,5 тыс.): 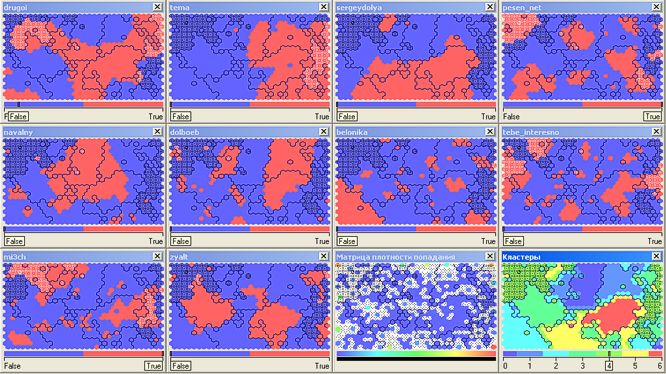 Кластер номер 6 вобрал в себя читателей (8 тыс.) без ярко выраженных пристрастий читающих практически всех топовых блоггеров одновременно:
Кластер номер 6 вобрал в себя читателей (8 тыс.) без ярко выраженных пристрастий читающих практически всех топовых блоггеров одновременно: 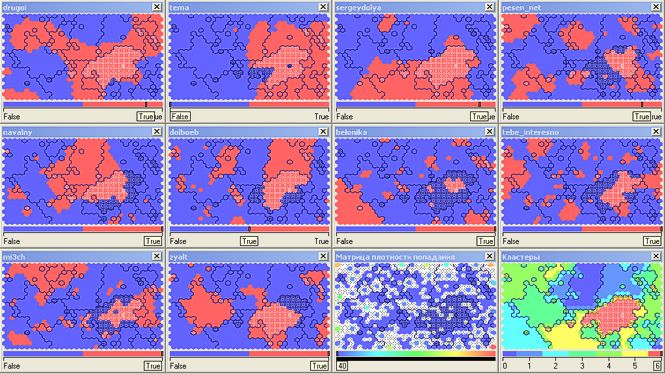 Ну и куда же сегодня без Алексея Навального (navalny)!? В страхе перед нашествием ботов я пишу эти строки… Кластер номер 0 (ой, только не бейте меня за ассоциации – в колодах карт Таро нулевая карта имеет название «Шут») охватывает 33 тыс. читателей (тут должна быть ремарка, но она пойдет в конце). Его было бы правильно объединить с кластером номер 1 (еще 16,5 тыс.) так же охватывающим политически активных топовых блоггеров (drugoi, dolboeb, zyalt):
Ну и куда же сегодня без Алексея Навального (navalny)!? В страхе перед нашествием ботов я пишу эти строки… Кластер номер 0 (ой, только не бейте меня за ассоциации – в колодах карт Таро нулевая карта имеет название «Шут») охватывает 33 тыс. читателей (тут должна быть ремарка, но она пойдет в конце). Его было бы правильно объединить с кластером номер 1 (еще 16,5 тыс.) так же охватывающим политически активных топовых блоггеров (drugoi, dolboeb, zyalt): 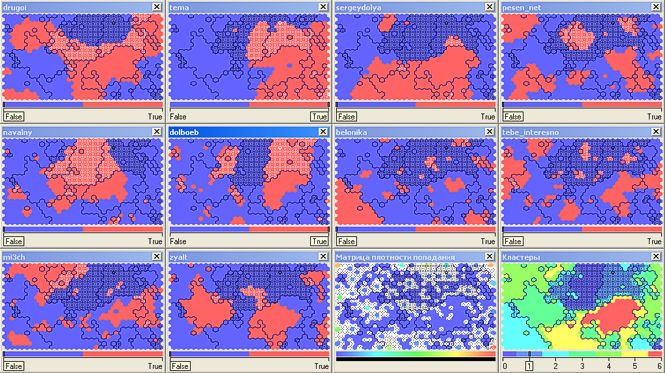
Техническая ремарка
Как я уже говорил, в данном случае наполнение и структура отображаемых кластеров зависит от их числа, которое может настраиваться. Например, для этой модели число «физических» кластеров, на которые разбилось множество читателей в результате обработки равно 19, но для наглядности я сделал более грубую модель с 7 «визуальными» кластерами. Точность такого разбиения (да и самого метода кластеризации через нейросети) не абсолютна, поэтому может получиться так, что в кластер «Навального» попадет пользователь его не читающий. Но эта погрешность, в принципе, не критична для поверхностного оценочного анализа.Вместо заключения
На этом я заканчиваю демонстрацию проделанной работы, а над прикладным ее значением (например, анализом ТОП-30 или ТОП-50 или специально сформированного списка) предлагаю подумать рекламодателям, использующих ЖЖ для продвижения своих товаров и услуг. На этом я заканчиваю демонстрацию проделанной работы, а над прикладным ее значением (например, анализом ТОП-30 или ТОП-50 или специально сформированного списка) предлагаю подумать рекламодателям, использующих ЖЖ для продвижения своих товаров и услуг. P.S. Пользователи ЖЖ, не зарегистрированные на Хабре, могут задать вопросы в моем блоге infist-xxi.livejournal.comОригинальный текст статьи Вы можете найти здесь
from inetpsy.ru